
El Ray Tracing es un algoritmo para renderizar escenas que ha sido ampliamente utilizado en el mundo de la animación offline pero que en entornos a tiempo real como son los videojuegos es ahora cuando empieza a despuntar. En este artículo os hablaremos de la evolución pasada, presente y futura del hardware respecto al trazado de rayos para que así os podáis hacer una idea de lo que nos podemos esperar.
Al igual que ocurrió con la rasterización, donde inicialmente era solo posible en superordenadores, luego en estaciones de trabajo y más tarde en ordenadores domésticos con tarjetas 3D, el trazado de rayos o conocido por su nombre en inglés «Ray Tracing» ha tenido la misma evolución y lo que hace años era solo posible con sistemas muy potentes y caros cada vez está más al alcance de todo el mundo.
La evolución del hardware respecto al Ray Tracing

Es por ello que hemos decidido hacer una retrospectiva para mostraros la evolución del hardware en lo que al Ray Tracing respecta; esta evolución la hemos dividido en cinco etapas distintas, y en ellas no solamente hablaremos de los métodos del pasado sino también de los métodos que vamos a ver en el futuro cercano y que por tanto se van a implementar en futuras generaciones de las GPUs que equiparán nuestros PCs.
Etapa 1: Renderizado a través de la CPU

Se ha de tener en cuenta que las GPUs durante un largo tiempo se encontraron atadas al algoritmo de rasterización por lo que no eran adecuadas para renderizar escenas basadas en el Ray Tracing, el cual utiliza un algoritmo diferente.
¿La solución que existía para cuando se quería renderizar una escena vía trazado de rayos? Tirar de CPUs de múltiples núcleos y aunque esto ya forma parte de la historia fue el planteamiento que Intel quería ejecutar con su cancelado y fallido Larrabee hace poco más de una década, el cual no era más que varios núcleos x86 en una configuración muy parecida a una GPU.

Esta solución resulta que es la más ineficiente debido a que las CPUs son sistemas escalares pensados para funcionar con una sola tarea por hilo de ejecución y en comparación con una GPU tienen muy pocos hilos funcionando simultáneamente, forzando a que sea necesario tener que crear superordenadores de decenas por no decir cientos de CPUs para el renderizado.
Etapa 2: Ray Tracing en la GPU a través de la Compute Shaders
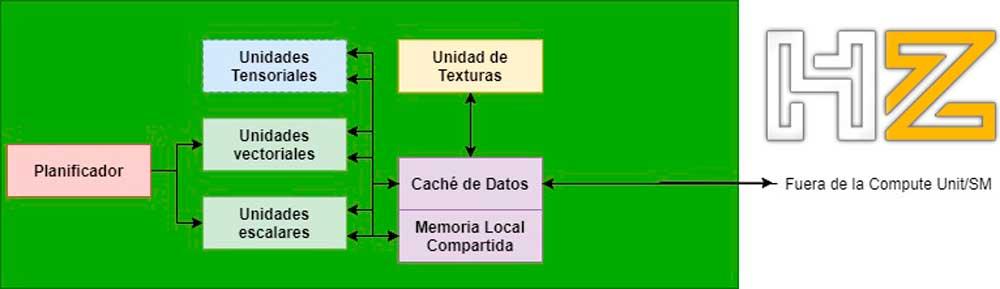
A partir de DirectX en su versión 11 y de OpenGL en su versión 4 apareció un nuevo tipo de programas shader para las GPU llamados Compute Shaders, los cuales no están asociados a una etapa del pipeline gráfico.
Gracias a ellos las GPUs pudieron centrar su potencia total o parcialmente en resolver problemas más allá de la rasterización y entre ellos se hizo posible la implementación del trazado de rayos en la GPU, no a la suficiente velocidad como para permitir el renderizado a tiempo real, pero sí de cara a implementar un pipeline de sucesivas etapas vía Compute Shaders.
Pero no fue hasta DirectX 12 que se empezó a poder plantear un pipeline de renderizado completo para el Ray Tracing donde cada etapa de las específicas es un Compute Shader realizando una de estas etapas en concreto.
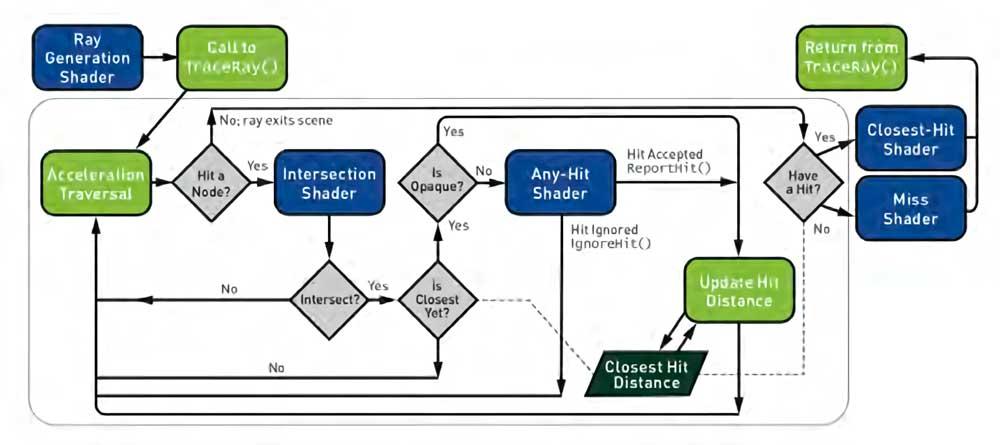
Este pipeline es el que se acabó estandarizando a partir de 2018 como preliminar del DirectX Ray Tracing y fue posteriormente adoptado también por Vulkan; no obstante, esta primera implementación en las GPUs para el trazado de rayos a tiempo real no era lo suficientemente buena en cuanto a rendimiento y se hizo necesario hacer cambios en la clásica Compute Unit/SM.
Etapa 3: Unidades de intersección
Algo que es habitual en diseño de hardware es crear aceleradores para que realicen tareas que reiterativas y repetitivas por un coste en área y energía mucho más bajo que un procesador completo, la idea es descargar dichas tareas en esos procesadores especializados.
Este tipo de unidades son habituales en las GPUs. Por ejemplo, de cara a la rasterización nos encontramos con unidades de función fija que realizan operaciones como el rasterizado de los triángulos, el filtrado de texturas, etc. Estas unidades están cableadas y siempre realizan la función a partir de los datos de entrada que se le otorgan y es por eso se llaman de función fija, porque no podemos cambiar su función, es decir, no son programables. La ventaja de este tipo de unidades es que nos permite realizar esos cálculos específicos utilizando unidades muy pequeñas, de muy poco consumo y que funcionan completamente en paralelo.
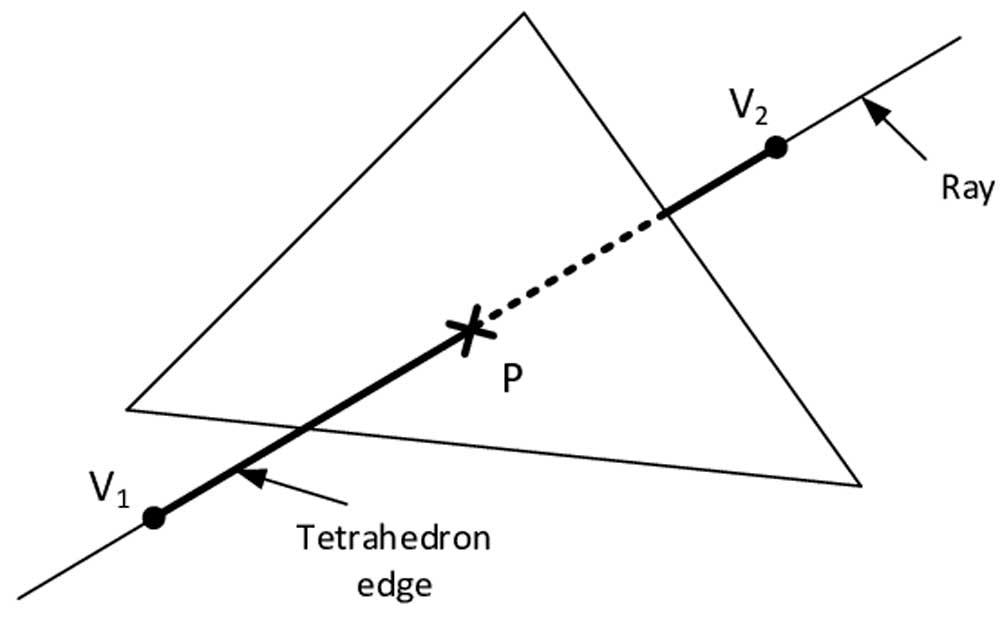
En el Ray Tracing, cada uno de los rayos que son generados durante la escena van a impactar con uno o varios objetos de la misma por lo que es necesario realizar ese cálculo de manera continua y reiterada que llamamos intersección, por lo que es el tipo de proceso ideal que termina en forma de unidad especializada funcionando en paralelo.
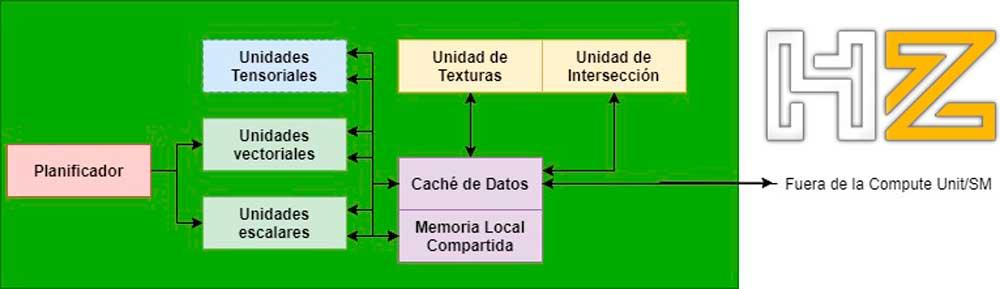
En el caso de las unidades de intersección, dentro de la GPU se encuentran dentro de las Compute Units/SMs en las de gráficas de AMD / NVIDIA (en todo caso hablamos del mismo tipo de unidad en ambos casos, pero con diferente nombre) y se comunican con las ALUs encargadas de ejecutar los shaders a través de la caché de datos dentro de la misma unidad.
Etapa 4: Unidades de recorrido del árbol BVH
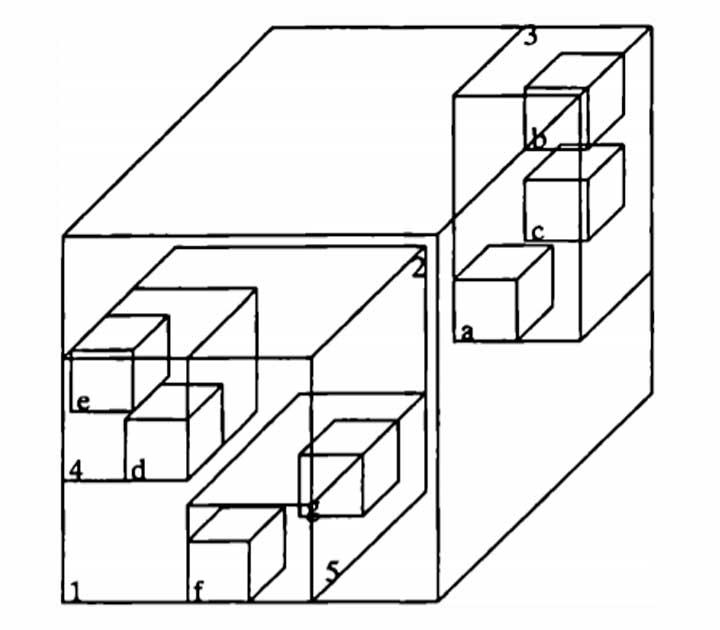
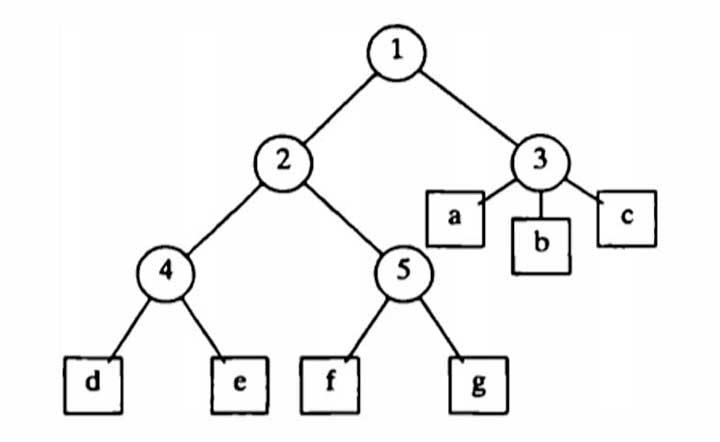
El BVH es una estructura de datos espacial que almacena de manera ordenada la geometría de la escena. Con tal de acelerar el proceso de cálculo de la intersección lo que se hace es realizar éste sobre el árbol BVH en vez de hacerlo píxel por píxel.
Sin las unidades encargadas de recorrer el árbol BVH es necesario hacerlo con el programa compute shader, pero con dichas unidades implementadas a nivel del hardware nos olvidamos de tener que realizar este proceso.
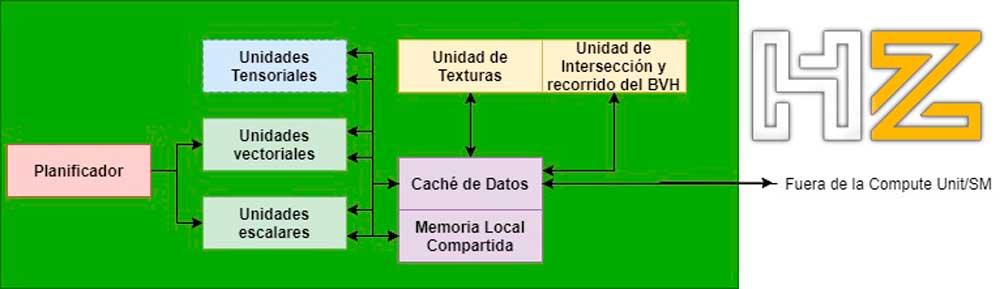
Dicho de otra forma, una unidad de recorrido va a ir generando todos los rayos y el recorrido de todos ellos por el árbol BVH de manera automática sin participación de un programa shader e interactuará con la unidad de intersección. Ambas al terminar el proceso enviarán los resultados de vuelta.
Hay que tener en cuenta que en la actual versión de DirectX 12 Ultimate esto no forma parte de la especificación mínima y es necesario controlar la creación de nuevos rayos a partir de la intersección de otros con los objetos a través del Ray Generation Shader. Por lo que el uso de esta unidad es limitado, ya que se prefiere darles el poder a los desarrolladores de juegos por el momento acerca de la densidad de rayos en la escena.
Etapa 5: Ray Tracing Coherente
La siguiente etapa en la evolución de las GPUs de cara al Ray Tracing será el añadido de una unidad de coherencia en la GPU, pero antes de nada hemos de entender a lo que nos referimos con coherencia con la memoria desde el punto de vista de cualquier procesador, siendo ésta que la visión de la memoria de cada procesador es la misma, en concreto de las GPUs contemporáneas.
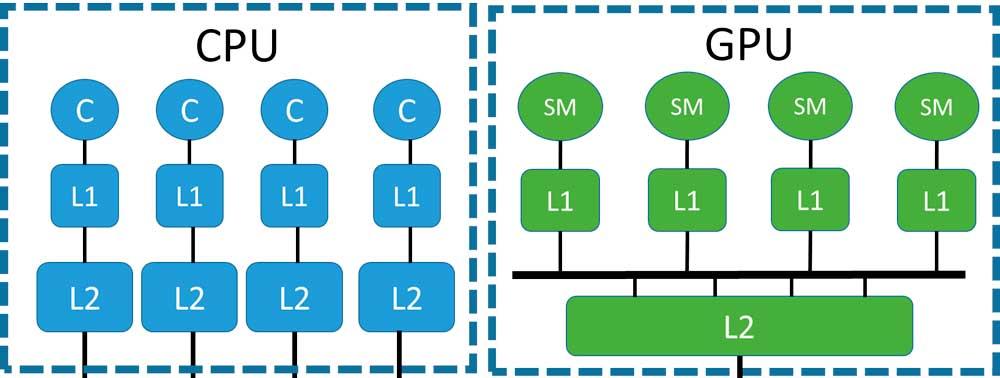
Sí queremos entender el problema con la coherencia de memoria, entonces hemos de comprender cómo funciona el mecanismo de cachés de un cualquier sistema con múltiples procesadores, tanto si hablamos de una CPU como de una GPU.
- Las memorias cachés no son RAM en sí mismas, sino que almacenan porciones concretas de la RAM o de los niveles de caché superiores.
- Los niveles inferiores de la caché y más cercanos a los procesadores contienen copias de porciones de datos de las cachés de niveles superiores.
Por lo tanto, si queremos realizar un sistema coherente se ha de crear un mecanismo que cuando un núcleo u otra unidad de la GPU cambie el valor de un dato también se cambien todas las copias que hacen referencia a esos datos en todas las caches de manera simultánea así como en la VRAM.
Entonces, ¿con qué problema se enfrentan ahora las GPUs? Antes hemos comentado que la unidad de intersección y de recorrido del BVH tienen acceso a la caché de datos de la Compute Unit/SM, pero al no existir un mecanismo de coherencia, cuando se realiza un cambio sobre los datos en una Compute Unit/SM entonces el resto de unidades lo desconocen, y esto lleva a que buena parte de los cálculos de intersección y recorrido se repitan incluso si han sido ya realizados por otras unidades.
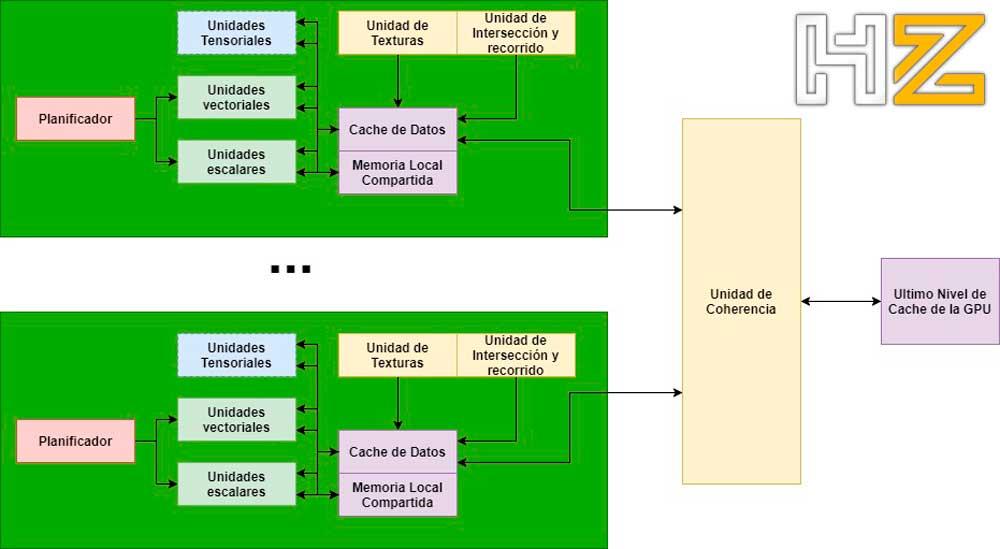
La unidad de coherencia es una o varias unidades de hardware encargadas de avisar de los cambios en el contenido de las cachés a todas las Compute Units/SMs, por lo que se trata de un hardware difícil de implementar debido a la cantidad de intercomunicaciones que necesita.
En una CPU la coherencia se puede conseguir de manera fácil por el hecho que tenemos muy pocos núcleos en su interior, pero en una GPU la mayor cantidad de núcleos hace que el sistema de coherencia sea difícil de implementar; hay que tener en cuenta que la cantidad de caminos de datos que es necesario implementar es n2 donde n es la cantidad de elementos interconectados entre sí.
Dado que las GPUs van de camino a dividirse en chiplets, es muy posible que esta unidad de coherencia se convierta en un chiplet en sí mismo o se encuentre en la parte central encargada de comunicar las diferentes partes entre sí. En todo caso a este punto aún no hemos llegado y dado que los cambios a nivel de la arquitectura se están dando en periodos de 2 a 5 años aún nos va tocar esperar un poco.
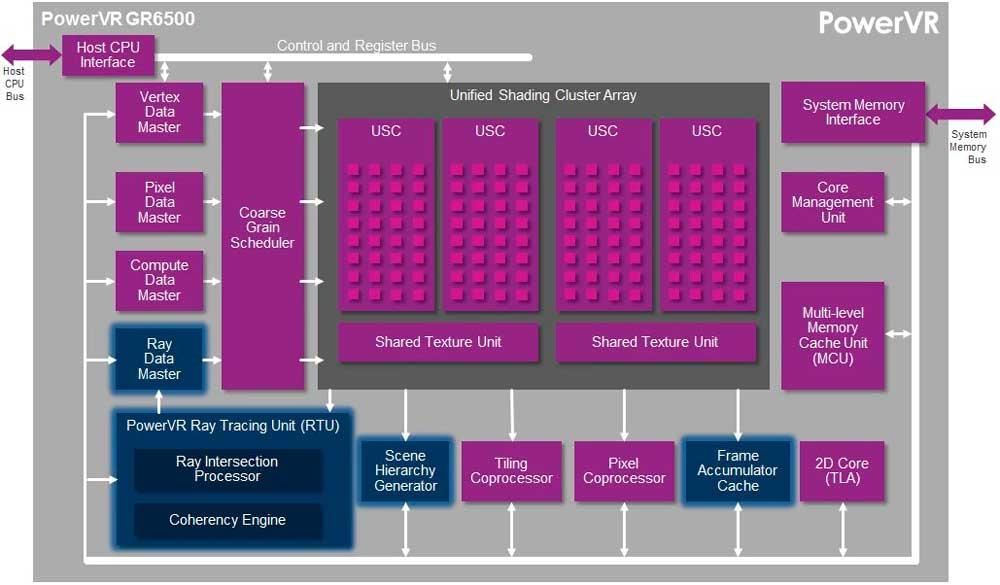
Donde sí que se encuentra implementado el Coherency Engine es en la arquitectura PowerVR Wizard de Imagination, ya que hace años que esta implementada en ese hardware, pero NVIDIA y AMD no la han implementado aún en sus GPUs y hay que tener en cuenta que tienen un planteamiento un «poco» diferente al de Imagination; en todo caso es la siguiente evolución de cara al Ray Tracing.