
DirectX es una API que nos lleva acompañando desde Windows 95, se trata de una API de alto nivel que representa de manera abstracta diferentes componentes del PC para facilitar la comunicación de los programas con los diferentes periféricos. DirectML es una de las ramas de DirectX 12 pensaba para facilitar el uso de las unidades especializadas en inteligencia artificial que se han implementado en el hardware en los últimos años.
Con la llegada de las consolas de nueva generación en combinación con las AMD RX 6000 por fin tenemos a ambos fabricantes de tarjetas gráficas con GPUs capaces de ejecutar algoritmos pensados para la IA, no obstante, el planteamiento de ambas empresas es distinto. Mientras que NVIDIA intenta atar a los desarrolladores a librerías que están exclusivamente pensadas para su hardware, AMD ha optado por no desarrollar herramientas propias y utilizar la API de Microsoft DirectML.
Teniendo en cuenta las dos consolas de siguiente generación, PlayStation 5 y Xbox Series X, entonces está claro que de cara al uso de algoritmos de inteligencia artificial en los juegos entonces AMD va a ganar, pero hemos de partir de la idea que DirectML no está diseñado para un hardware en concreto y es completamente agnóstico de plataforma.
DirectML funciona bajo cualquier tipo de procesador
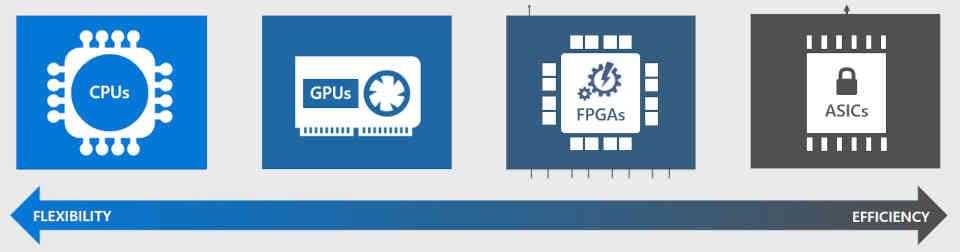
DirectML parte de la idea de que podemos ejecutar cualquier tipo de instrucción en cualquier tipo de procesador, pero no todos son igual de eficientes, esto significa que algunas arquitecturas serán más eficientes que otras a la hora de ejecutar estos algoritmos.
El tipo de unidad más rápida son los llamados ASIC, esto son procesadores neurales (NPUs) cuyas ALUs son arrays sistólicos y están optimizadas para ejecutar estos algoritmos más rápidamente, ejemplos de este tipo de unidades son las siguientes:
- Los Tensor Core de las NVIDIA RTX
- Las NPU de los diferentes SoC para Smartphones
El segundo tipo de unidad son las FPGA configuradas como si fueran ASIC, pero que debido a la mayor área de los FPGA y la menor velocidad de reloj son menos eficientes.
El tercer tipo son las GPUs, estas no tienen unidades especializadas, sino que se trata de ejecutar los algoritmos de IA como si fuesen programas Compute Shader, no son tan eficientes como un FPGA o un ASIC, pero son mucho más eficientes que una CPU a la hora de ejecutar esta clase de algoritmos.

DirectML esta pensado para utilizar un ASIC si este se encuentra en el sistema, si no se encuentra entonces buscara la GPU para ejecutarlo y en última instancia la CPU como recurso muy desesperado. En cambio librerias como NVIDIA cudNN solamente funcionarán con la GPU de NVIDIA y a través de los Tensor Cores, ignorando otro tipo de unidades en el sistema.
Super-Resolución

Se le conoce como Super-Resolución a través de la IA al hecho de utilizar un algoritmo de inteligencia artificial para generar una versión a más resolución de una imagen dada, lo cual tiene como ventaja poder aumentar la resolución de salida de los juegos sin tener que renderizarla nativamente y consumiendo muchos menos recursos: La Super-Resolución solo merece la pena cuando el tiempo de renderizar a una resolución nativamente es mayor que el tiempo de renderizar en reanderizar a menor resolución y realizar el algoritmo de escalado a través de la IA.

Hay que tener en cuenta que existen dos tipos de algoritmos de super-resolución:
- Los del primer tipo son utilizados en películas y por tanto en fotogramas ya predefinidos que se actualizan cada x ms y donde la decodificación de los mismos más el escalado vía IA se hace con muy poca potencia necesaria. Los sistemas de escalado automático de algunos televisores se basan en algoritmos de este tipo.
- El segundo tipo es lo que hemos visto con el DLSS de NVIDIA, en los juegos a tiempo real no existe una versión predefinida de la imagen en memoria, esta se ha de generar y entonces el procesador que ejecuta el algoritmo tiene pocos milisegundos para aplicarlo. No obstante hay que aclarar que lo que hace el DLSS no es algo exclusivo de NVIDIA y cualquiera puede hacer una contrapartida.
El primer tipo es muy fácil entrenarlos ya que podemos utilizar la versión a mayor resolución una película para que la IA se pueda retro-alimentar durante el proceso de entrenamiento. Pero en un videojuego es diferente, cada fotograma no existe previamente por lo que el entrenamiento utilizado es mucho más complejo y requiere de una supervisión continua, de ahí a que por ejemplo NVIDIA tenga que utilizar a los superordenadores Saturn-V para entrenar la IA.

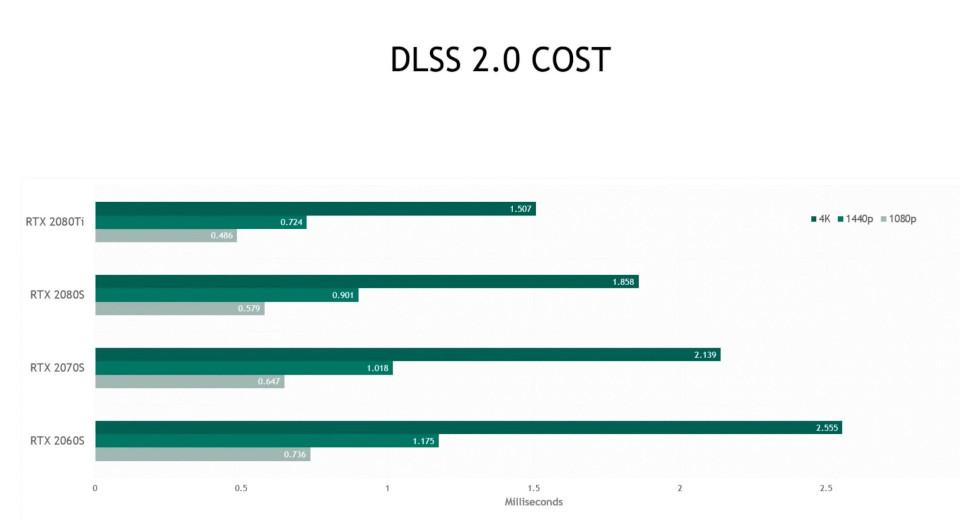
El otro problema es a la hora de ejecutar el algoritmo que se ha conseguido con el entrenamiento. En el caso del DLSS 2.0. un tipo de algoritmo del segundo tipo, sus Tensor Cores tienen 1. 5 ms de media para realizar todo el proceso, lo que supone necesitar una alta potencia para hacerlo esa velocidad, de ahí las ingentes cantidad de TFLOPS en los Tensor Cores.
En DirectML se puede aplicar un algoritmo del mismo estilo, pero se ha de entender que cuanto menos potente sea la parte que aplica el algoritmo entonces más rápida tendrá que ser la GPU que renderizando la escena con antelación con tal de darle tiempo a la unidad encargada de aplicar el algoritmo de super-resolución.
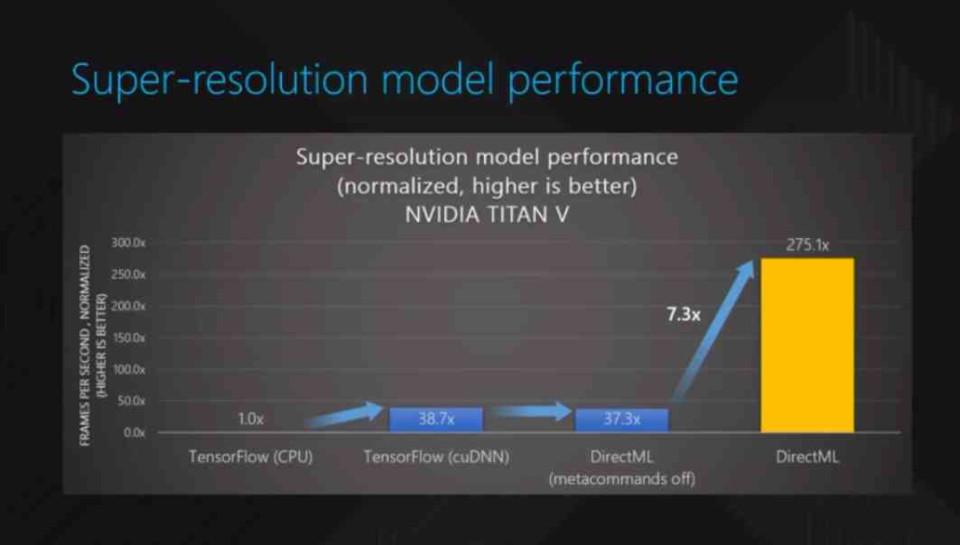
Es posible que con el tiempo veamos una desaparición del DLSS 2.0 a favor del algoritmo del DirectML, pero hay que ver si las GPUs de AMD son lo suficientemente rápidas y aguantan el tipo frente a las de NVIDIA. Los Tensor Core de NVIDIA pueden realizar cálculos en FP16 e Int8 a un ratio de 4:1 respecto a cualquier GPU de AMD con especificaciones similares. No en vano, DirectML fue presentado por primera vez haciendo uso de los Tensor Cores de una NVIDIA Volta.
Hay que tener en cuenta que estos algoritmos no te generan la imagen a 4K nativo sino que hacen una estimación del valor de cada pixel y hay que tener en cuanta que existe un rango de error que puede llevar a representaciones alejadas de lo que se espera. Por eso los juegos que soportan este tipo de técnicas no lo hacen de salida y el soporte es limitado para la gran mayoría de juegos, pero cuando la IA genera imagenes muy cercanas a los 4K nativos entonces el ahorro es significativo.