La Computación en Memoria es uno de los paradigmas que nace del hecho de colocar la memoria RAM muy cercana al procesador, hasta el punto de colocarse en el mismo encapsulado o incluso dentro del propio chip. Dicho paradigma va a ser muy importante en un futuro ya que muchos procesadores se van ver acelerados en velocidad acercando la memoria físicamente al procesador.
¿Qué no es la computación en memoria?
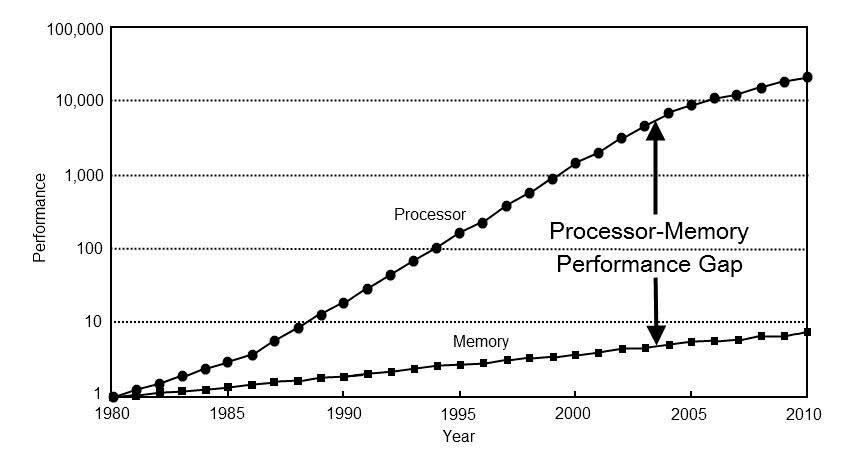
Uno de los problemas universales de cara al rendimiento de una CPU es la distancia que hay con la memoria.
Con el tiempo se han utilizado mecanismos para paliar dicha distancia, como es por ejemplo el uso la memoria caché, pero a medida que esta diferencia va creciendo se hace sumamente importante acortarla acercando la memoria al procesador, y es aquí donde entra el concepto de la computación en memoria.
El concepto es acercar la memoria al procesador de tal manera que la latencia de las instrucciones, la cual es la cantidad de ciclos de reloj que tarda una CPU en realizar dicha instrucción, se acorte en el proceso.
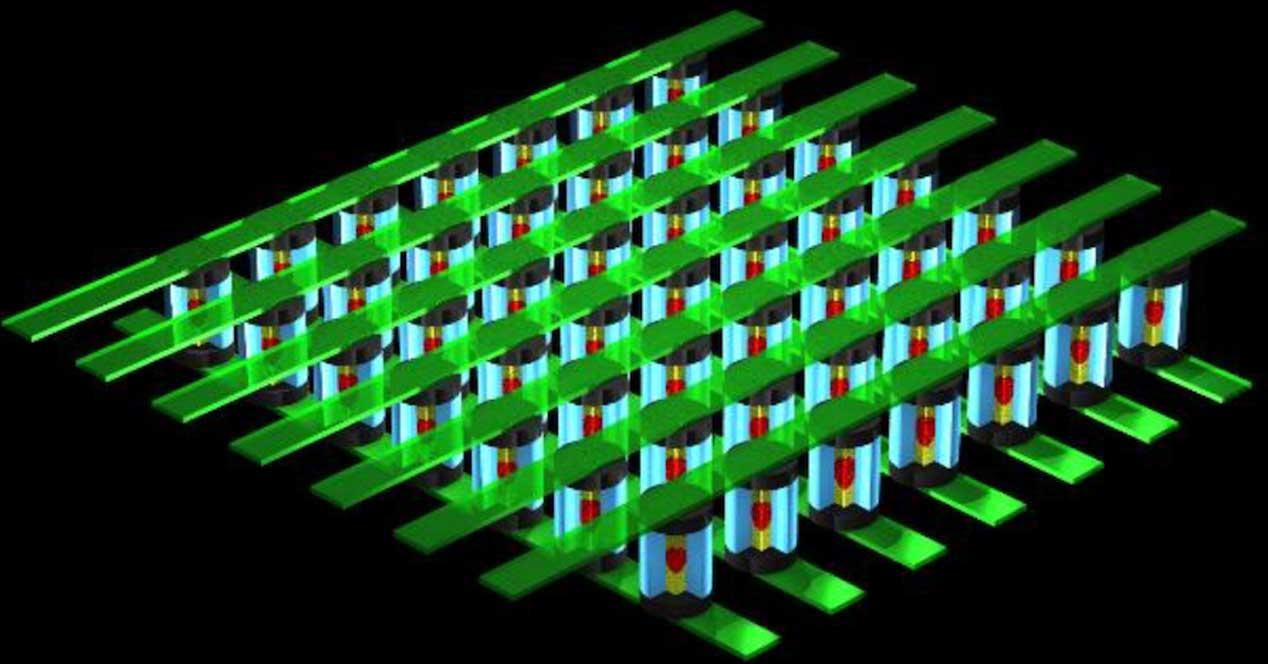
La llegada de los procesadores 3DIC (que suelen ser procesadores con varios núcleos y/o memoria apilada) van a permitir que dentro del procesador hayan densidades de memoria muy grandes, las cuales van a lograr que dicha memoria dentro del procesador (o altamente cercana al procesador) se pueda utilizar como si fuese memoria RAM o como una parte de la RAM, pero de alta velocidad.

El otro motivo de ello es el hecho que las instrucciones que se ejecutan en la RAM convencional tienen un consumo energético que es una orden de magnitud y a veces hasta dos órdenes de magnitud respecto a que los datos se encuentren dentro de la caché. Como un procesador tiene un presupuesto energético limitado para funcionar es importante que las instrucciones consuman lo mínimo posible con tal de ganar rendimiento/consumo en su diseño.
En el paradigma actual la velocidad de reloj de un procesador depende del consumo energético de las instrucciones más caras en ese aspecto. La idea a futuro es aprovechar que la memoria esté cercana al procesador para que ciertas instrucciones se realicen con un consumo energético más bajo que ahora y permitir velocidades de reloj dinámicas según el tipo de instrucción. Por ejemplo, las instrucciones más ligeras en cuanto a energía se podrán ejecutar a velocidades de reloj más altas que otras debido a su menor consumo energético.
Es decir, las CPUs del futuro no irán a una velocidad de reloj fija, sino que irán fluctuando de manera dinámica según cada instrucción o el conjunto de instrucciones que se ejecute en cada momento.
Mejoras en el ancho de banda al integrar la memoria en el procesador.
La interfaz de memoria con la RAM a nivel físico es en serie, esto significa que si quieres un gran ancho de banda has de hacer más grande el controlador y debido a que el controlador de memoria se encuentra en la periferia del procesador esto supone aumentar el tamaño del chip y con ello sus costes. La otra opción es aumentar la velocidad de reloj, pero esto aumenta de manera exponencial el consumo energético en conjunto entre la RAM y el procesador que la utiliza.
La idea de integrar la RAM en el mismo encapsulado o en el mismo chip es poder utilizar interfaces de memoria más anchas, normalmente en matriz. Por ejemplo, un bus de 1024 bits ocuparía un espacio muy grande en el perímetro, pero podemos conectar verticalmente la memoria al procesador o conectar ambos por separado a un sustrato común.
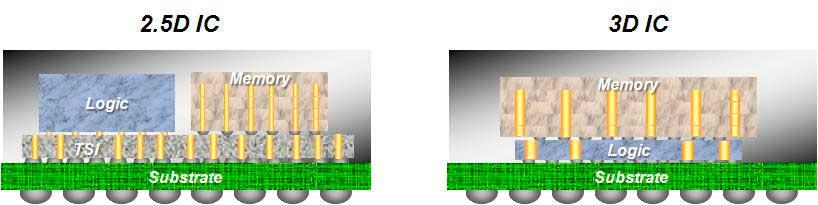
Esto permite que una interfaz de 1024 bits por ejemplo se pueda convertir en una de 32×32 ocupando mucha menos área. La idea de tener una gran cantidad de pines para la intercomunicación significa poder alcanzar velocidades de reloj mucho más altas sin tener que tirar de velocidades de reloj muy altas.
Hay que tener en cuenta que por ejemplo tener un bus de 64 bits a 2 GHz no te va a consumir lo mismo que uno de 128 bits a 1 GHz sino el doble, por eso es importante poder aumentar la cantidad de interconexiones con la memoria.
La idea en la RAM computacional es tener anchos de banda mucho más grandes que en la memoria convencional, al mismo nivel casi que una caché, de tal manera que las instrucciones que dependen del ancho de banda por un lado y las que dependan de la latencia se vean beneficiadas a partes iguales de este paradigma.
El hándicap para la memoria computacional: la temperatura
El problema de sumar un procesador y una memoria juntos, para crear lo que llamamos computación en memoria, es que ambos generan una gran cantidad de temperatura en conjunto, por lo que nos encontramos con el problema que pese a que disminuye el tiempo por instrucción en lo que a numero de ciclos se refiere. Se puede ver limitada en la velocidad de reloj con tal de evitar que se alcancen grandes temperaturas en el proceso que frían al procesador.
Es el motivo además por el cual es una solución sumamente cara y es posible que no la veamos en los mercados domésticos. El hecho de que un procesador con memoria pueda alcanzar altas velocidades de reloj de manera estable es una rareza y dichos procesadores puede que terminen siendo tan caros que sean inviables para el ámbito comercial.
En realidad, este el motivo por el cual en la gama de procesadores de alto rendimiento no se habla de apilar la memoria en el mismo chip a medio plazo, pero sí que se habla de añadir procesadores en la memoria, lo cual no es lo mismo que la memoria en los procesadores. A este concepto se le llama RAM Computacional o computación en memoria o procesador en memoria.