
Las RTX 3000 salieron hace unos meses reemplazando a las RTX 2000, pero, ¿cómo se comparan ambas arquitecturas y cuáles son los cambios que hay de una generación a la otra, es un salto tan espectacular como vende NVIDIA o más bien son cambios pequeños? Os explicamos las diferencias entre las arquitecturas Turing y Ampere.
¿Merece la pena el cambio de una RTX 2000 por una equivalente en las RTX 3000? Desde nuestro punto de vista si quieres el máximo rendimiento si, pero, al mismo tiempo creemos que es importante desmitificar ambas generaciones de GPU, por lo que las vamos a comparar.
En que son iguales Turing y Ampere en cuanto a arquitectura

Hay una serie de elementos en los que no han habido cambios de una generación a otra, por lo que no han habido cambios internos y siguen funcionando igual en Ampere respecto a Turing.
La lista de elementos que no se han modificado la inauguran los procesadores de comandos en la parte central de ambas GPU. La cual es la parte encargada de leer las listas de comandos desde la RAM principal y organizar el resto de elementos de la GPU. Seguido de las unidades de función fija para el renderizado vía rasterización: unidades de rasterizado, teselación, texturas y los ROPS.
Tampoco ha cambiado la estructura de memoria interna, es decir, la jerarquía de cachés que sigue siendo igual en Ampere y no ha variado respecto a Turing, ya que sigue siendo la misma en ambas arquitecturas, siendo el único elemento de la jerarquía de memoria la interfaz de memoria GDDR6X que utilizan las GPU basadas en el chip GA102 de NVIDIA como por ejemplo la RTX 3080.
En que elementos se diferencian Turing y Ampere

Tenemos que irnos a dentro de las unidades SM para ver cambios en las RTX 3000 basada en Ampere respecto a las RTX 2000 basadas en Turing y son cambios que se han realizado en tres frentes distintos:
- Las unidades de coma flotante en FP32
- Los Tensor Cores.
- Los RT Cores.
Fuera de estos elementos y fuera de la cantidad de unidades SM, la cual es más alta en las GeForce Ampere que en las GeForce Turing no hay ningún cambio, por lo que NVIDIA ha reciclado buena parte del hardware de la anterior generación para crear la nueva. Y antes que saquéis la conclusión de que esto es algo negativo, dejad que os diga que común en diseño de hardware.
Cambios en coma flotante en las SM de GeForce Ampere

En todas las GeForce hasta Pascal, todas las unidades de coma flotante eran llamadas por parte de NVIDIA núcleos CUDA. Así sin más, sin aclarar lo que significaba eso más allá que hacían cálculos en coma flotante. Daban a entender que eran unidades de coma flotante de 32 bits de precisión.
Realmente los núcleos CUDA en realidad eran realidad unidades logicoaritméticas para el cálculo en coma flotante de 32 bits, pero también unidades del mismo tipo para enteros de 32 bits. ¿La particularidad? Funcionaban conmutadas, de tal manera que no podían funcionar ambos tipos al mismo tiempo.

Con Turing cambio la cosa y apareció lo que se llama ejecución concurrente, el motivo es que las listas de hilos de ejecución de la GPU combinaba hilos por enteros y coma flotante y no llegaba a la ocupación máxima de slots de la unidad SIMT con cada sub-ola, por lo que NVIDIA decidió en Turing aplicar la ejecución concurrente. En la que una ola de 32 hilos de ejecución se puede ejecutar de manera combinada entre las ALU de enteros y las de coma flotante al mismo tiempo, siempre y cuando estas se encuentren disponibles.
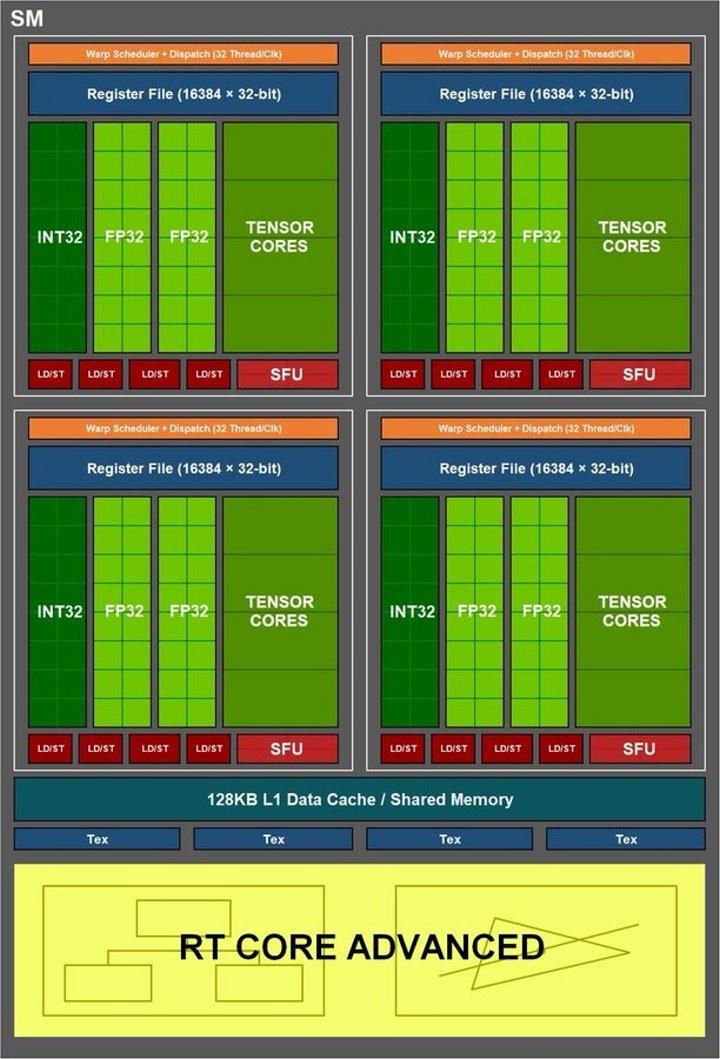
Lo cual significa que la distribución de hilos de ejecución de una ola de 32, el cual es el tamaño estándar de las GPU de NVIDIA, se puede distribuir en hasta 16 hilos de enteros y 16 hilos de coma flotante. Pero, alguien en NVIDIA se le ocurrió proponer un cambio para Ampere, el cual consiste en que set de ALU de enteros este conmutado con un segundo set de ALU de coma flotante, lo cual no requiere cambiar el resto del SM.
Por lo que en determinados momentos y cuando se cumple la condición que entra una ola de 32 hilos en coma flotante, la velocidad de calculo, medida en TFLOPS, se duplica. Aunque solo cuando se cumplen en esas condiciones y si tuviésemos un dispositivo para ir midiendo la tasa de TFLOPS veríamos que no es la que dice NVIDIA, que da el pico máximo en sus especificaciones, sino que tendría oscilaciones.
Tensor Cores en GeForce Ampere

Los Tensor Cores son arrays sistólicos que se estrenaron por primera vez en las GPU NVIDIA Volta, y se tratan de arrays sistólicos que son el tipo de unidad de ejecución utilizada para acelerar algoritmos basados en la inteligencia artificial. Dichas unidades al contrario que los RT Cores utilizan la unidad de control del SM y no se pueden utilizar al mismo tiempo que las unidades de coma flotante y de enteros, por lo que pese a que pueden funcionar de manera concurrente lo hacen quitando potencia el resto de unidades excepto los RT Cores.
Si sumamos la cantidad ALU que forman los RT Cores entre una generación y la otra veremos que hay la misma cantidad pero con una configuración distinta. En Turing tenemos 8 unidades, 2 por sub-core, de 64 ALU cada una en una configuración Tensor 4 x 4 x 4. Mientras que en Ampere los Tensor Cores tienen una configuración de 4 unidades, 1 por sub-core, con 128 ALU por cada uno de ellos.
RT Cores en GeForce Ampere
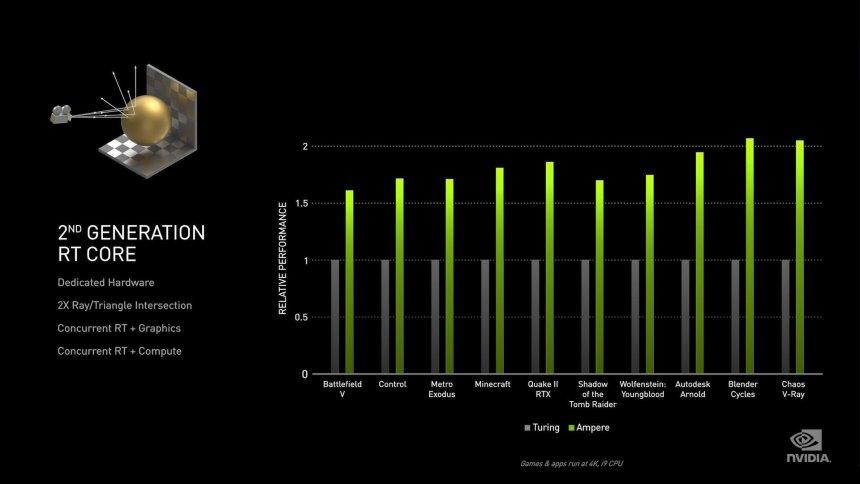
Los RT Cores son la parte menos conocida de todas, ya que NVIDIA no ha dado ninguna información acerca de cuál es su funcionamiento interno. Sabemos lo que hace, cuál es su funcionamiento, pero desconocemos cuáles son los elementos en su interior y que cambios han habido de una generación a otra.
Lo primero que llama la atención es la mención por parte de NVIDIA que los RT Cores ahora pueden hacer el doble de intersecciones por triángulo, lo cual no significa el doble de intersecciones por segundo. El por qué de ello es que a la hora de recorrer el árbol BVH lo que hace es ir haciendo la intersección de las cajas que son los diferentes nodos del árbol y solo la intersección final del árbol es la que se hace con el triángulo, la cual es la más compleja de realizar. Las unidades de cálculo de la intersección de las cajas son mucho más simples, en Turing tenemos en teoría cuatro unidades que funcionan en paralelo para ir recorriendo los diferentes niveles de un árbol y una sola unidad que realiza la intersección del rayo con el triángulo.
El segundo cambio a nivel de hardware es la capacidad de interpolar el triángulo según su posición en el tiempo, lo cual es clave para la implementación del Ray Tracing con Motion Blur, técnica aún inédita en los juegos compatibles con Ray Tracing. En el caso de que haya otros cambios NVIDIA no ha informado públicamente de ello y por tanto no podemos sacar más conclusiones.