Intel Gen 11: desvelamos todos los detalles de la arquitectura para sus nuevas tarjetas gráficas

Todos estamos expectantes ante lo que Intel puede hacer con su nueva generación de tarjetas gráficas, donde ha invertido mucho dinero y las expectativas son muy grandes por ello. Hoy estaremos un paso más cerca de desvelar muchas de las incógnitas que el gigante azul nos tiene preparadas, ya que por primera vez conoceremos en que se basa su arquitectura Gen11, base de su futura GPU Xe.
Intel Gen 11: hasta un Teraflop de rendimiento con soporte para todas las APIs principales
Intel ha remodelado desde cero su arquitectura para entrar en el mercado de gama alta con sus nuevas tarjetas gráficas, pero antes, pretende competir contra AMD y sus APU mediante su nueva iGPU Gen 11 GT2.
Lo que aquí veremos es la implementación que Intel destinará a dichas GPUs y que servirá de paso previo a lo que deben incluir a gran escala con memoria apilada 3D.
Las nuevas iGPU Gen 11 de Intel llegarán en un proceso de 10 nm FinFET, aplicando mejoras significativas en la micro arquitectura para proporcionar un mejor rendimiento por vatio. Gen 11 soporta todas las APIs principales que estamos acostumbrados a ver, es decir, DirectX, OpenGL, Vulkan, OpenCL y Metal.
Gen 11 constará de 64 EUs (Execution Units), que, según Intel, ofrecen una capacidad de cómputo 2,67 veces mayor que Gen 9. Además de dicha mejora de EUs, se ha mejorado la compresión, aumentado la memoria caché L3 y aumentado el ancho de banda de la memoria principal.
Coarse Pixel Shading (CPS) y Position Only Shading Tile Based Rendering (PTBR)

Las mejoras no quedan solo aquí, ya que Intel ha incluido nuevas características que permiten un mayor rendimiento al reducir el trabajo redundante.
Dichas mejoras son llamadas CPS y PTBR, o Coarse Pixel Shading y Position Only Shading Tile Based Rendering.
Coarse Pixel Shading permite un nuevo control de los píxeles de sombreado, preservando la calidad de visualización de la resolución mientras se renderiza más lentamente los valores de color en el Coarse Pixel Rate. Esto viene provocado porque hoy en día la mayoría de juegos renderizan a una resolución más baja y luego terminan escalándola a la resolución de la pantalla, mejorando los FPS, pero perdiendo calidad visual en el proceso.
Con CPS, Intel evitaría en gran medida este problema, ganando rendimiento por el camino.
PTBR en cambio lo que busca es no salir en ningún momento (siempre que sea posible) a buscar ancho de banda en la memoria RAM.
Esto es algo que ya hemos visto tanto en AMD como en NVIDIA y ahora Intel pretende reducir el ancho de banda de la memoria mediante las Tile-Based.
Para ello se ha agregado un pipeline de geometría paralela que actúa como un motor de selección de las baldosas, utilizado antes del render-pipeline para visibilizar el pre-pass por baldosa.
Arquitectura del SOC
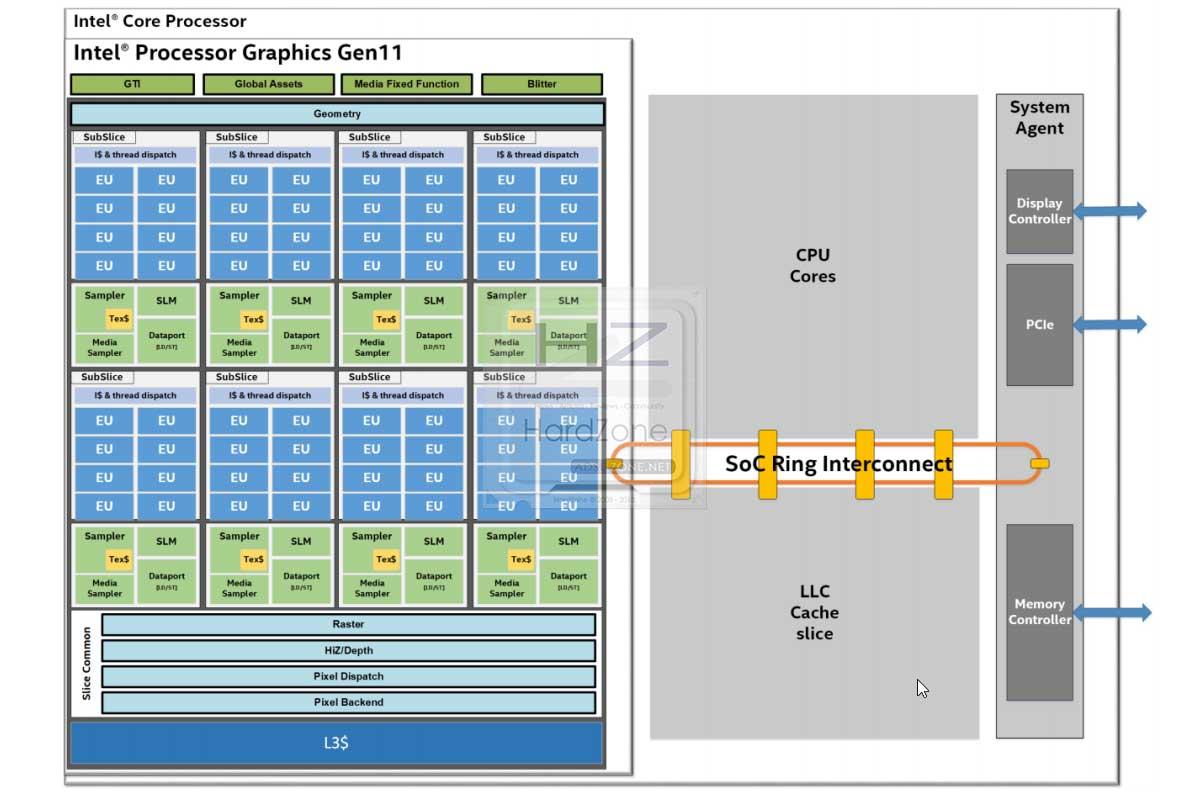
Los procesadores con iGPU son complejos SOCs que integran múltiples núcleos, donde en este caso encontraremos los de CPU, los de su iGPU Gen 11 y además algunas funciones fijas adicionales.
Esta nueva arquitectura Gen 11 implementa múltiples dominios de reloj que han sido divididos de la siguiente manera:
- Un dominio de reloj para la CPU.
- Otro para la iGPU.
- Y el último para el Ring Interconnect.
Esto permite que esta arquitectura Gen 11 sea extensible a una amplia gama de productos, dando lugar a distintos SOCs, donde el más importante sin duda es el Ring Interconnect, ya que el concepto de bus es parecido al que usa AMD con Infinity Fabric.
Ring Interconnect es un nuevo bus que interconecta en la matriz los núcleos de la CPU, las memorias caché y sus niveles, la iGPU y todos aquellos chips que estén conectados fuera del SOC, como por ejemplo la memoria del sistema.
Para ello se hace uso de una topología de interfaces locales dedicadas para cada «agente» conectado, y donde cada procesador incluye una caché compartida llamada LLC o Last Level Cache, que también va conectada al Ring Interconnect y comparte información con la iGPU o dGPU.
Arquitectura del procesador gráfico Gen 11
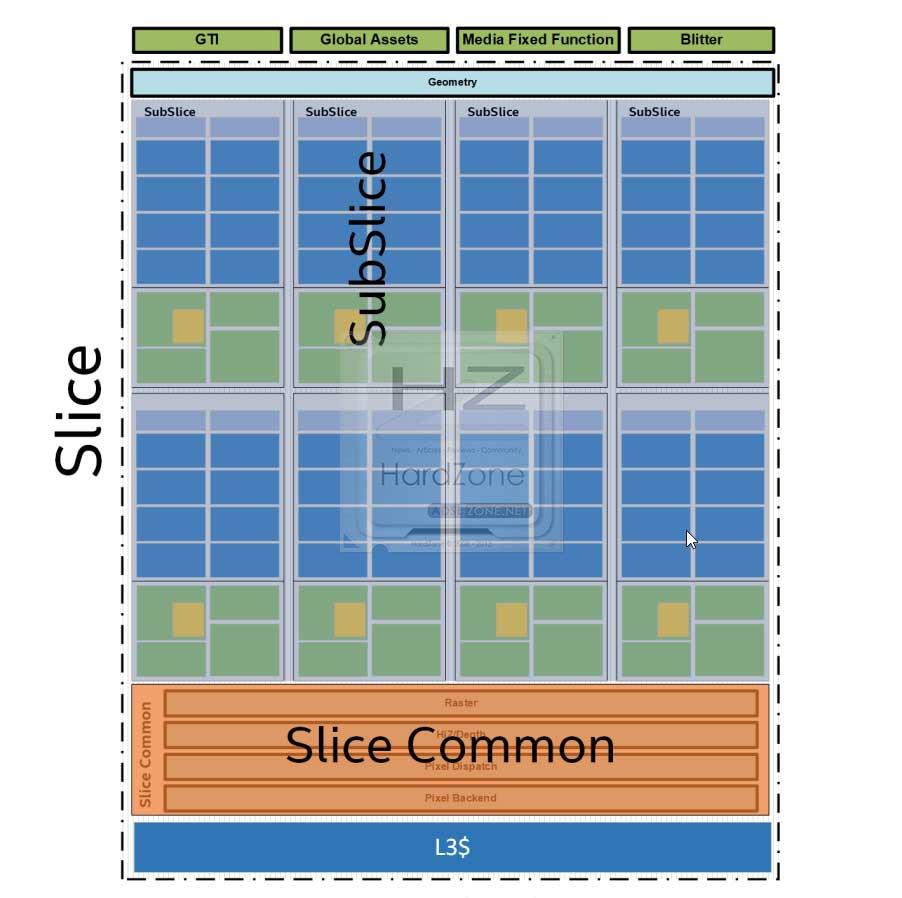 Gen11 llegará como un diseño monolítico que tiene importantes mejoras micro arquitectónicas que irán enfocadas a mejorar el rendimiento por vatio y con ello la eficiencia.
Gen11 llegará como un diseño monolítico que tiene importantes mejoras micro arquitectónicas que irán enfocadas a mejorar el rendimiento por vatio y con ello la eficiencia.
Esto es debido a que Gen11 es una evolución de Gen 9, pero con mejoras en todos los aspectos para eliminar cuellos de botella y mejorar la eficiencia del pipeline.
Esta nueva arquitectura Gen11 se compone de 64 EUs, y estará dividida en varios apartados principales: Global Assets, Blitter en 2D, Media FF y GTI, donde la unidad mínima es el llamado Slice.
Cada Slice alberga un motor de Geometría 3D propio, ya que dentro de cada Slice existen 8 Sub-Slice, unidades más pequeñas pero dependientes y que contienen las UEs.
Dentro de cada Slice, encontraremos el llamado Slice Common, que contiene el resto de bloques de función fijos y que incluye el render Pipeline, la caché L3, el motor de rasterización, Dispacht y HiZ/Depth.
Global Assets, Media FF y GTI
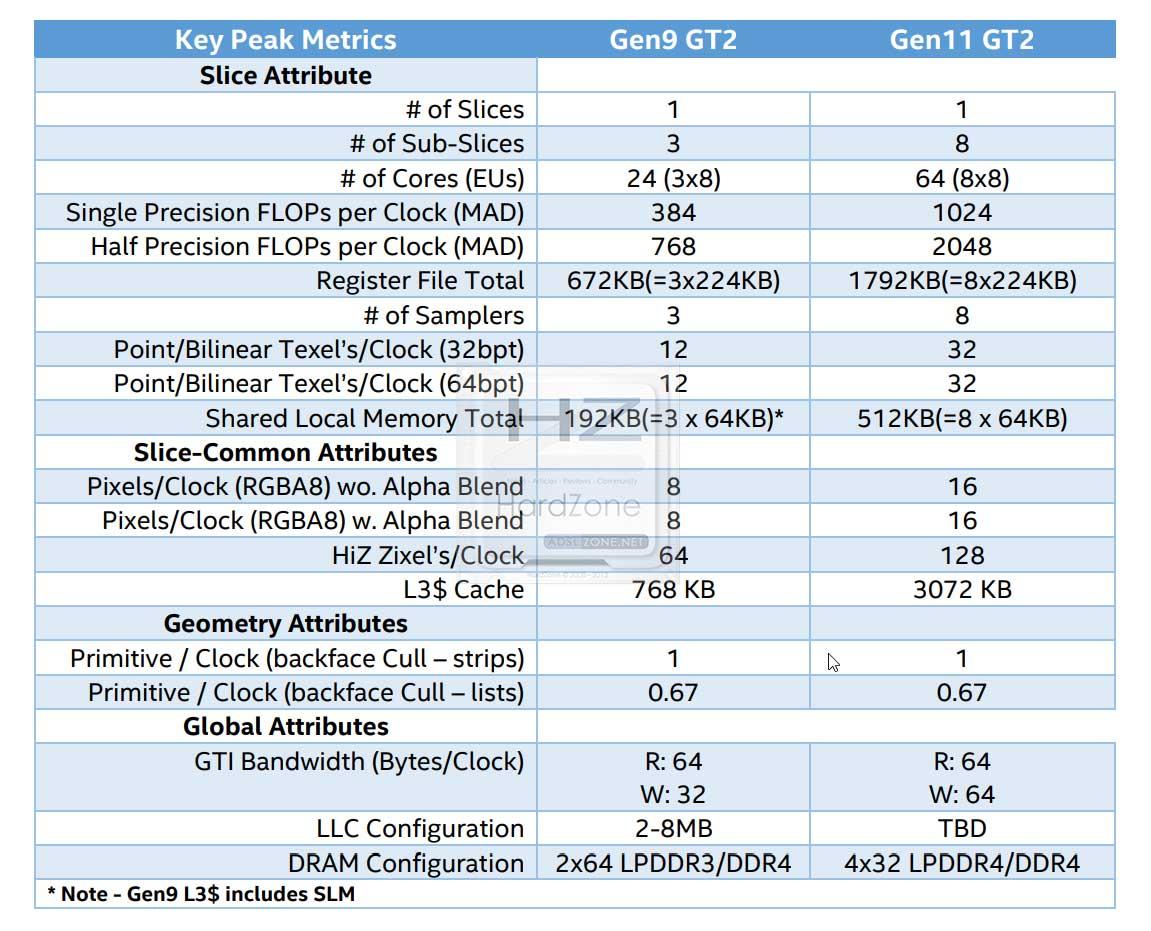 Global Assets presenta una interfaz de hardware y software de GPU al resto del SOC, permitiendo que sea GTI (Graphics Technology Interface) la puerta de enlace entre la memoria LLC, la RAM del sistema o la jerarquía de la memoria interna.
Global Assets presenta una interfaz de hardware y software de GPU al resto del SOC, permitiendo que sea GTI (Graphics Technology Interface) la puerta de enlace entre la memoria LLC, la RAM del sistema o la jerarquía de la memoria interna.
Debido a esta nueva función, Intel ha dotado a GTI de un mayor ancho de banda, pasando de 32B/clock a 64 para las operaciones de escritura, mejorando en el camino la latencia.
Arquitectura de los Slice

Todas las iGPU basadas en Gen11 tendrán dentro de cada Slice ocho Sub-Slice y al mismo tiempo, dentro de cada Sub-Slice, tendremos 8 EUs para hacer el total de 64 EUs del que hemos hablado antes.
Recordemos que dentro de cada Slice se incluyen el motor de Geometría, la caché L3 y el Slice Commom.
Motor de Geometría
Gen11 contiene dentro del Slice un motor de Geometría 3D que a su vez incluye el front-end para renderizar las APIs como DX12 o Vulkan.
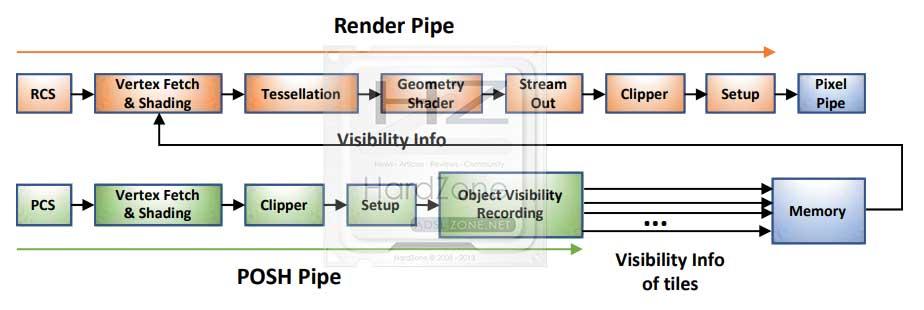
Además, incluye POSh (Position Only Shading) el cual es usado para poder implementar el ya visto PTBR. Este punto es necesario para lograr trabajar con los VF o Vertex fetch, los cuales son los responsables de la obtención de los datos de los vértices almacenados en la memoria que después serán usados, para finalmente escribir los resultados en el búfer interno.
Como todos sabemos, un vértice tiene más de un atributo (posición, color, coordenadas etc.) por lo que los juegos actuales cada vez cargan más los vértices con atributos para intentar realizar el mayor trabajo en el mínimo tiempo.
El problema es la saturación que ello produce debido a la complejidad que han adquirido y a la carga de trabajo que esto supone.
Para solucionarlo, Intel ha aumentado el input rate de los VF de 4 atributos por clock a 6, mejorando la eficiencia de la caché de datos de entrada.
Esto permite un mayor número de las llamadas «back to back draw calls«, que, aunque se han reducido con APIs como DX12 y Vulkan, siguen siendo indispensables para los VF.
Intel ha mejorado dentro del motor de Geometría el rendimiento de la teselación, donde cifra un aumento de 2X el rendimiento de esta Gen11 comparado con Gen 9.
Arquitectura de Sub-Slice
Esta será la unidad que determinará la potencia de cada modelo de iGPU de Gen11. Cada producto será diseñado para incluir un número de estos Sub-Slice, mientras que los arquitectos podrán elegir el número de EUs que desean incluir dentro de ellos.
Cada Sub-Slice contiene una Unit-Dispatcher, que soportará cachés de instrucciones, una unidad 3D de Muestreo de Texturas, una unidad de Muestreo de Media y un Puerto de Datos.
La unidad básica: arquitectura de EU Gen11
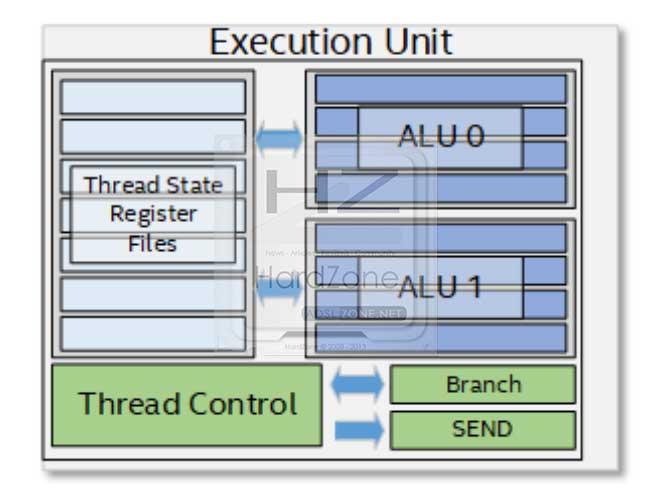
El bloque donde todo se cimienta son los EU o Execution Units. Estas unidades son una combinación de subprocesos múltiples simultáneos (SMT) y los llamados fine-grained interleaved multi-Threading o IMT.
En resumen, son procesadores de cómputo que resuelven problemas múltiples mediante instrucciones únicas a través de unidades lógicas aritméticas de datos (SIMD ALUs).
Mediante múltiples hilos se consigue realizar el cálculo de enteros y punto flotante de alto rendimiento, de manera que, dependiendo del software usado, dichos hilos podrían usar el hardware dentro de un EU para ejecutar el mismo kernel o un código distinto desde un núcleo diferente.
Cada EU tiene dos unidades SIMD ALUs, donde estas pueden ejecutar hasta cuatro operaciones FP o INT de 32 bits o hasta 8 de 16 bits, es decir, cada EU puede ejecutar 16 operaciones de punto flotante FP32 por ciclo y 32 de FP16.
Además, cada EU es totalmente multiproceso, no dejando que se genere latencia interna por clock.
Shared Local Memory (memoria local compartida o SLM)
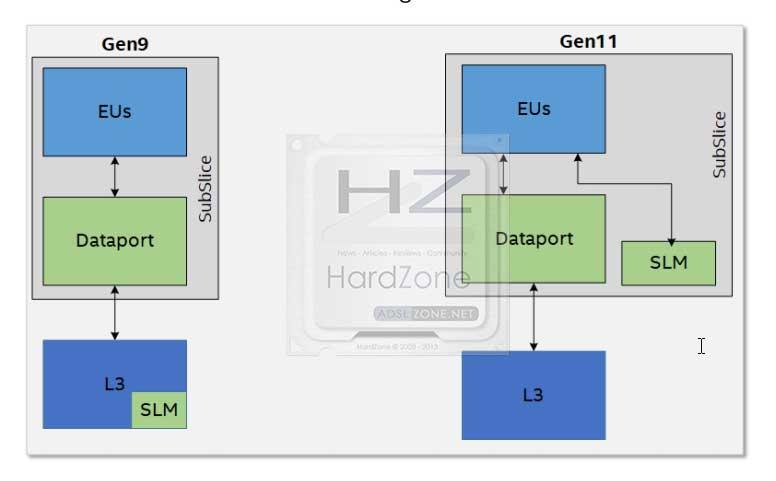
La SLM para Gen11 tendrá un tamaño de 64 KB accesible desde cualquiera de los 8 EU en cada SubSlice, ya que la propia SLM y el acceso a la memoria se dividen para acceder por un lado al DataPort, mientras que los EU pueden acceder directamente a la SLM al mismo tiempo.
La proximidad que se adquiere permite una baja latencia y mayor eficiencia, ya que el tráfico generado en la SLM no interfiere con el que se genera en la L3 a través del DataPort o el Sampler.
Slice Common: Raster, Depth, Pixel Dispatch, Pixel Backend/Blend y L3 Data Cache
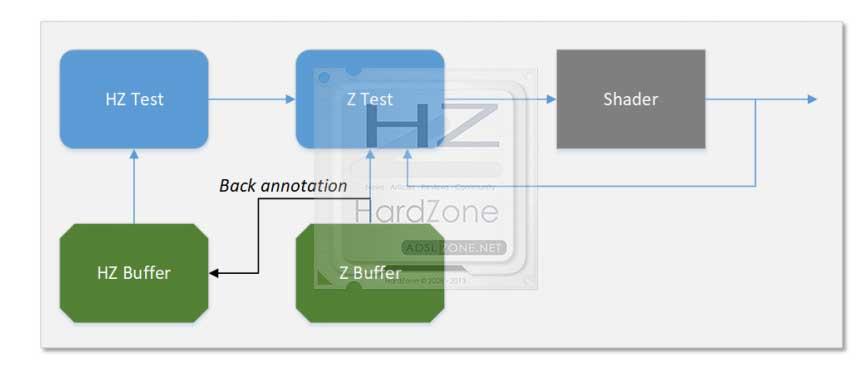
No entraremos demasiado en detalles aquí, ya que la explicación es demasiado extensa y la gran mayoría son tecnicismos irrelevantes para comprender que hacen, y cómo se han mejorado.
El motor de rasterizado convierte los polígonos en un bloque de píxeles llamados subspans. Intel ha dotado a su arquitectura Gen11 de un aumento de la tasa de conversión, ya que ahora pueden realizar 16X para 1xAA y 4X para 4xMSAA.
Dicha mejora ha sido cifrada en aproximadamente 8X, lo cual es un salto gigantesco.
La profundidad o Depth, se utiliza para realizar la eliminación de la superficie oculta del Buffer Z, descartando píxeles en función de una comparación de los datos entrantes.
Dicha comparación se basa en dos niveles de granularidad: gruesa (Coarse) y fina (fine), donde las primeras son realizadas por HiZ en bloques de 8X4 píxeles, y la fina se realiza mediante Bloque Z.
El siguiente en ser analizado es el Pixel Dispatch, el cual acumula información de los subspan, previamente rasterizados, y envía el subproceso a los EU. Además, elige el ancho que usarán las SIMD, eligiendo entre SIMD8, SIMD16 y SIMD32, maximizando con ello la eficiencia de cada ejecución y minimizando la utilización del archivo de registro.
Pixel Backend en cambio representa la última etapa del «rendering pipeline«, que incluye la caché para mantener los valores del color, donde las funciones de combinación de esos colores se originan en varios formatos de superficies, mejorando con ello la compresión del color sin pérdida.
Por último, toca hablar de la L3 Data caché. Y es que Intel ha aumentado su tamaño hasta los 3 MB. Cada aplicación tiene flexibilidad en cuanto a la cantidad de la estructura de memoria L3 que se asigna, dividiéndose en dos partes: «Application L3 data cache» y «System buffers for fixed-function pipelines».
Esto se explica debido a que en no pocas ocasiones la renderización 3D asigna más L3 como buffer del sistema, para así soportar el pipeline de funciones fijas.
En Gen11 en vez de acceder parcialmente a un par de 32B, se accede a un solo módulo de 64B, mejorando con ello la eficiencia.
Mejoras en la eficiencia de la memoria
La eficiencia de la memoria es un pilar dentro de cualquier arquitectura existente, ya que los juegos tienden a utilizar un mayor ancho de banda por las llamadas «texturas dinámicas», lo que añadido a unas resoluciones cada vez más grandes, hacen de la optimización de la memoria un tema crucial.
La compresión sin pérdida tiene como objetivo mitigar esto, aprovechando que los bloques de píxeles adyacentes dentro de un «render target» varían levemente o son simplemente similares, permitiendo dicha compresión y ahorrando ancho de banda de escritura cuando los datos son expulsados de la L3 a la memoria del sistema.
Intel Gen11 permite dos nuevas optimizaciones para la compresión de color sin pérdida: soporte para formatos de superficie sRGB para texturas dinámicas, y al mismo tiempo, el algoritmo de compresión explota la propiedad de que un grupo de píxeles puede tener el mismo color cuando está sombreado usando Coarse Pixel Shading.
Esto permite que el objeto de procesamiento (render target) y el búfer de profundidad permanezcan en la memoria de chip durante la renderización mientras que las overdraws se finalizan.
Arquitectura de memoria unificada
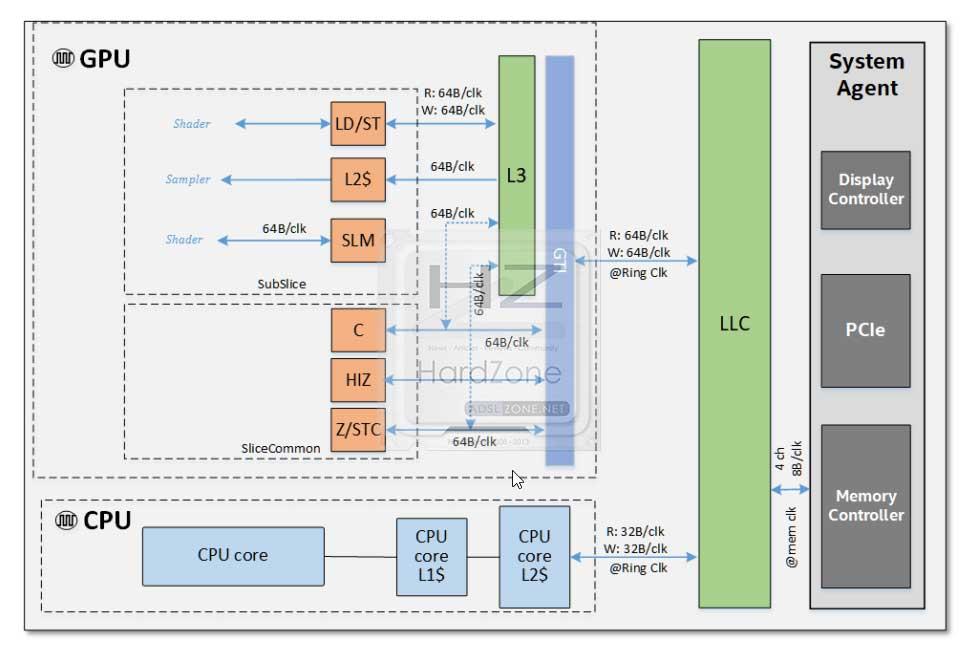
Es bien sabido que la implementación de la memoria unificada de Intel ha dado grandes resultados al compartir memoria física DRAM con sus CPUs.
Esta arquitectura ha permitido una gran potencia y eficiencia, permitiendo realizar transferencias en el búfer de las llamadas «Zero Copy» entre la CPU y la iGPU.
Estas Zero Copy son simplemente la ausencia de la copia del búfer, ya que la memoria física es compartida.
Gen11 es compatible con LPDDR4, ya que todo el subsistema de memoria está optimizado para una baja latencia y un alto ancho de banda, donde este presenta varias optimizaciones.
Una de ellas es una nueva estructura de políticas de enrutamiento (Fabric Routing Policies), donde además tendremos una mejora en los algoritmos de la programación de los controladores de memoria para un mayor ancho de banda y mejor eficiencia global.
Dicho sistema de memoria, junto a su subsistema, incluyen características QOS para ayudar a equilibrar las demandas del ancho de banda, independientemente de quien lo necesite.
Controlador de pantalla para Gen11
Para finalizar las novedades y mejoras de la arquitectura Gen11, queda por conocer qué ha introducido Intel en este apartado.
Los de Santa Clara se han centrado específicamente en la mejora de la gestión de energía, con dos mejoras claras: Panel Self Refresh y Display Context Save and Restore.
Panel Self Refresh permitirá que el controlador de pantalla baje los clocks para un estado de energía de baja potencia, que, cuando se combina con Display Context Save and Restore puede ahorrar mucha más energía al apagar adicionalmente la alimentación de la pantalla en un estado llamado Power SRAM, que será restaurado cuando vuelva la energía.
Todo esto permite que el SOC alcance unos estados de energía profundos mientras aun se está ejecutando.
Además, se ha añadido una ruta de procesamiento de los píxeles más amplia, en respuesta al aumento de las resoluciones de los monitores actuales, permitiendo que la frecuencia requerida se reduzca en un 50%.
Y hasta aquí todas las novedades sobre la arquitectura Intel Gen11 que veremos en los procesadores Ice Lake y más adelante como base de la GPU dedicada que competirá contra AMD y NVIDIA, la Intel Xe.